Em 1992, ocorreu um incidente curioso no mercado americano de brinquedos. A Mattel, fábrica da Barbie, lançou o modelo Teen Talk Barbie, que tinha dentro um gravador: quando a criança apertava um botão, a boneca dizia algumas frases pré-gravadas. A idéia era uma novidade na época, e a boneca começou a vender muito bem (mais de 300 mil unidades em um ano). A maior parte das frases eram as tolices que se esperaria que saíssem de uma Barbie (“Ok, me encontre no shopping”, “Será que um dia nós teremos roupas que chegam?”, “Quer sair pra fazer compras?”, etc.).
Uma delas, porém, causou uma reação que a fábrica não esperava: a frase “Math class is tough!” (“Aula de Matemática é dureza!”). Provavelmente alguém da fábrica pensou que o público iria achar a frase “cute” (uma gracinha, fofinha), mas os professores e as feministas não concordaram. O Conselho Nacional de Professores de Matemática considerou-a “prejudicial ao esforço feito para encorajar meninas a estudar matemática”, e outras organizações de mulheres também protestaram. Os resultados foram, primeiro, que a fábrica acabou tendo que retirar a boneca do mercado; segundo, que esta Barbie se tornou uma celebridade, com vídeos no Youtube, página na Wikipedia, e um valor para colecionadores estimado em uns US$ 500 (enquanto a maioria das Barbies custam hoje em torno de US$ 20 na Amazon).
O interessante de tudo isto é que, apesar da overreaction do público, a Barbie no fundo estava certa : aulas de matemática são mesmo difíceis. Ninguém que tenha passado por uma escola pode negar isto; e quem estudou alguma das “ciências exatas” ou Engenharias em geral não tem muita saudade das aulas de Cálculo ou de Álgebra Linear. Não são apenas as aulas que são difíceis. A Matemática pode ser fascinante (não é a toa que jogos matemáticos como sudoku são populares em todo o mundo), mas sem dúvida é difícil – não apenas para as Barbies, mas para qualquer pessoa, independentemente de sexo, raça, idade ou crença.
O ramo da Matemática que nos interessa aqui – as Probabilidades – parece ser mais difícil para os estudantes do que os outros ramos. Vários de seus teoremas e resultados “elementares” vão contra o senso-comum; nada em Probabilidades é obvio – se parece óbvio, provavelmente é porque está errado. Mesmo os problemas que hoje são considerados fáceis e resolvidos como exercício logo nas primeiras aulas são desafios para quem os encontra pela primeira vez.
Para lembrar quão difíceis são as Probabilidades, uma busca na história pode nos mostrar exemplos de problemas nos quais grandes matemáticos se confundiram no passado, e cometeram erros que até hoje são comentados nos livros.
O exemplo mais bem conhecido é o de d’Alembert (1717- 1783), matemático, físico e filósofo francês (retratado ao lado por Quentin de La Tour, 1753). D’Alembert foi um dos editores da Encyclopédie – a enciclopédia francesa que, junto com a inglesa Encyclopaedia Britannica e a alemã Brockhaus Enzyklopädie, foram no século XVIII as precursoras das enciclopédias modernas. Entre os cerca de 1700 textos que escreveu para a obra estava o artigo “Croix ou Pile” (cara-ou-coroa), no qual d’Alembert afirmava que a probabilidade de se obter pelo menos uma cara no lançamentos de duas moedas não é ¾ (como afirmavam Pascal e Fermat), mas sim 2/3. Uma vez que o jogo pára se houver cara na primeira moeda (não é preciso jogar de novo a moeda, se já saiu uma cara), há apenas três resultados possíveis: cara na primeira moeda; cara na segunda moeda; coroa nas duas moedas. Laplace fez referência a este erro no seus livro clássico [1], publicado muito depois, o que tornou d’Alembert célebre não apenas por seus muitos acertos, mas também por este único erro. O historiador Charles Boyer chegou a afirmar que “D´Alembert, diferentemente de Euler, é notado na história das Probabilidades principalmente por ter se oposto às opiniões geralmente aceitas” [2], o que é um exagero (a Wikipedia traz uma longa lista das contribuições de d’Alembert à Matemática).
Cramér, estatístico sueco do século XX, menciona outro francês, Giles de Roberval (1602 –1675), que também já tinha recusado os resultados de Pascal e Fermat, um século antes, e tirado as mesmas conclusões erradas [3]. Atualmente, este problema com duas moedas é considerado ‘fácil’ e é geralmente usado como exemplo na primeira aula de Probabilidades (neste site, é o Exemplo 1 da seção 3.1.3).
Um exemplo mais complicado é o problema de Monty Hall (veja o texto anterior neste blog). Paul Erdős, quando viu pela primeira vez o problema, não conseguiu resolvê-lo, e não aceitou a resposta correta quando esta lhe foi apresentada. Vários dias depois, quando viu o resultado de simulações feitas em computador por um amigo, Erdős ficou convencido de que a resposta era mesmo trocar de porta; mesmo assim, nunca entendeu completamente a demonstração que lhe foi mostrada [4].
D’Alembert e Roberval, dois dos maiores intelectuais da história França, não conseguiram resolver um problema com duas moedas; e Erdős, um matemático com mais de 1400 artigos publicados, não conseguiu entender um problema com três portas. Para nós que ensinamos ou estudamos Matemática, isto pelo menos vai servir de consolo na próxima vez que não conseguirmos resolver um problema – se os grandes nomes do passado podiam errar de vez em quando, nós pobre mortais também podemos!
[1] Laplace (1840). Essai phylosophique sur les probabilités. 6ª. ed. Paris: Imprimerie de Bachelier.
[2] Cramér, Harald (1973). Elementos da teoria da probabilidade e algumas de suas aplicações. São Paulo: Edit. Mestre Jou. p. 13-14.
[3] Boyer, Charles. (1989). A history of mathematics. 2nd ed. John Wiley. p.455.
[4] Hoffman, Paul (1999). The man who loved only numbers. London: Fourth State, p. 237.
O cálculo de probabilidades costuma ser motivo de muita frustração para os alunos de Estatística. O que começa com historinhas aparentemente inofensivas sobre moedas e dados pode tornar-se um pesadelo, à medida que estes alunos são apresentados a uma maior variedade de problemas. Diferentemente do que ocorre em outras áreas da Matemática, conhecer algebrismos, fórmulas e procedimentos-padrão não é suficiente para a probabilidade. Atenção, leitura e interpretação são habilidades fundamentais neste campo. Já falamos disso neste blog (veja “As meias na gaveta”) – para os enunciados de problemas de probabilidades, a expressão idiomática que diz que “o diabo mora nos detalhes” é perfeita.
Ao longo de meu percurso acadêmico, como aluno de cálculo de probabilidades, perdi a conta do número de vezes em que fui apresentado ao Problema de Monty Hall. Quase sempre, o enunciado era feito como um desafio, ao final dos cursos. Apesar das incontáveis reprises, acompanhadas das mais variadas formas de se resolver o problema (umas mais esquemáticas, outras baseadas em fórmulas, e outras daquelas mais enigmáticas de uma só linha…) não houve uma vez em que eu tivesse ficado totalmente satisfeito com a resposta, o que me fez ficar irritado comigo mesmo e com o maldito desafio.
Ao começar a procurar a literatura sobre o problema, logo dei de cara com o livro “The Monty Hall Problem: The Remarkable Story of Math’s Most Contentious Brainteaser”, de Jason Rosenhouse [1].
Saber que existia um livro de 194 páginas inteiramente dedicado ao problema já me trouxe algum conforto: se tanto havia para falar sobre um único problema, talvez não houvesse tanto motivo para eu me culpar por não me satisfazer com as respostas, porque o negócio seria realmente complexo. Ao longo de um divertido primeiro capítulo, Rosenhouse deixa claro que eu não estava mesmo sozinho (inclusive estava muito bem acompanhado): por anos, o problema foi motivo de controvérsia e muita discussão, até mesmo entre matemáticos de primeira linha!
Mas, afinal, por que um problema enunciado em tão poucas linhas, conhecido desde a década de 70, persiste como um dos mais intrigantes e complexos desafios da probabilidade? Neste texto, comento sobre a origem, a solução, e trago idéias que podem servir como norte para discutir o Problema de Monty Hall.
A história
Em 1975, Steve Selvin, da Universidade da Califórnia, enviou uma carta ao editor da revista The American Statistician [2]. No número I do volume 29, foi publicado o que ele chamou de “A problem in probability”. O documento histórico, que pode ser encontrado facilmente na Internet (cheque as referências deste texto), pode ser visto ao lado.
O problema, apresentado na forma de uma história dialogada, consiste no estudo de estratégias para um programa de jogos. O apresentador pede que um participante escolha uma entre três caixas, A, B, e C. Dentro de uma delas, estão as chaves de um carro. Enquanto o participante escolhe sua caixa, o apresentador tenta persuadi-lo a rever sua estratégia.
Esta é a primeira versão do problema de Monty Hall de que se tem notícia. Monty Hall era o apresentador do programa de televisão americano chamado Let’s Make a Deal, onde membros da platéia participavam de provas que lhes poderiam render algum prêmio. No enunciado de Selvin, a grafia do nome do apresentador aparece como “Monte”, possivelmente para evitar problemas jurídicos ao se usar o nome de uma figura conhecida, mas já há bastante tempo a grafia “Monty” é o padrão difundido. Inclusive, o próprio Monty Hall chegou a dar seus palpites sobre o tal problema [3]. Apesar da publicação na The American Statistician e da retomada do problema pelo economista Barry Nalebuff em artigo de 1987 [4], pouco se discutiu sobre o assunto ao longo de alguns anos.
Foi em 1990 que o problema de Monty Hall foi ressuscitado e emergiu na cultura pop. Naquele ano, na edição de setembro, a revista de variedades americana Parade, publicou a seguinte pergunta, enviada pelo cientista Craig F. Whitaker à editora Marilyn Von Savant [5]::
Em tradução livre: Suponha que você esteja em um programa de jogos, e lhe seja dada a escolha entre três portas: Atrás de uma porta está um carro; atrás de outras duas, estão cabras. Você escolhe uma porta, digamos, No. 1, e o apresentador, que sabe o que está atrás das portas, abre outra porta, digamos, No. 3, que tem uma cabra. Ele então lhe pergunta, “Você quer mudar para a porta No. 2?”. É vantajoso mudar sua escolha?
Apesar de essencialmente tratar do mesmo problema, com os mesmos pressupostos do que havia sido publicado por Selvin em 1975, o enunciado da carta de Whitaker a Von Savant é o mais próximo daqueles que mais se encontram nos livros de Estatística até hoje. Após a resposta (parcialmente correta) da editora, o problema gerou toda uma discussão a partir da edição seguinte, na qual se engajaram vários debatedores e da qual derivaram outros quebra-cabeças ainda mais desafiadores. A história toda pode ser lida em seus pormenores no ótimo livro de Rosenhouse [1].
Vale destacar que, embora, como já dissemos, Monty Hall já tenha dado sua opinião sobre o assunto, é sabido que a tal prova das portas jamais existiu em seu programa. Justiça seja feita, o apresentador tupiniquim Sérgio Mallandro, sim, repetiu o jogo à exaustão desde 1987, quando comandava o infantil Oradukapeta. No quadro Porta dos Desesperados (uma sátira à Porta da Esperança, de Silvio Santos), uma criança tinha que escolher entre abrir a porta de três cabines. Atrás de uma delas, havia brinquedos, enquanto as outras duas revelavam um cacho de bananas e um adulto vestido de gorila, que corria atrás da pobre criança… Apresentar o problema como Problema do Sérgio Mallandro já me ajudou a fazer alguns alunos entenderem melhor, por incrível que pareça.
O problema
Vamos reler o enunciado do Problema de Monty Hall, em sua forma mais popular, como escrito por Whitaker:
Suponha que você esteja em um programa de jogos, e lhe seja dada a escolha entre três portas: Atrás de uma porta está um carro; atrás de outras duas, estão cabras. Você escolhe uma porta, digamos, No. 1, e o apresentador, que sabe o que está atrás das portas, abre outra porta, digamos, No. 3, que tem uma cabra. Ele então lhe pergunta, “Você quer mudar para a porta No. 2?”. É vantajoso mudar sua escolha?
Para a maior parte das pessoas com quem conversei sobre o programa diz, não faz diferença trocar de porta. A justificativa seria que, como foi descartada uma porta que não tinha o carro, ficamos com a decisão entre duas portas, com igual probabilidade de ter um carro. Como a porta Nº 1 teria probabilidade 1/2 de ter o carro, e a porta Nº 2, também 1/2, nenhuma das duas estratégias, ficar com porta Nº 1 ou mudar para a Nº 3, diminuiria ou aumentaria nossa probabilidade de escolher o carro. Logo, não faria diferença. Mas será que é simples assim?
Considero uma das maiores dificuldades em explicar a solução do Problema de Monty Hall não convencer alguém de uma resolução que leve à resposta correta. Acredito que convencer de por quê a idéia de que não faz diferença está equivocada (e, portanto, não haveria paradoxo) o ponto mais complicado.
Voltemos à expressão idiomática a que recorri no início do texto: “o diabo mora nos detalhes”. O raciocínio usado para justificar que não faz diferença trocar a porta ignora pressupostos que estão no enunciado, e substitui o problema por outro completamente diferente. Uma coisa seria alguém ligar a TV no meio do programa, ter perdido o início e chegado na hora em que o participante está diante de duas portas fechadas, uma com o carro e outra com uma cabra e, não fazendo a menor idéia do que aconteceu previamente, ou do que foi estabelecido, tentar descobrir a porta com o carro. No nosso caso, nós dispomos do enunciado, sabemos do jogo desde o início e, portanto, dispomos de informações a priori que não podem ser descartadas.
Vamos elencar, a partir do enunciado, os pressupostos do problema (ou “as regras do jogo”, como queira):
1) Duas portas têm cabras, uma porta tem um carro.
2) Monty Hall sabe em que porta está o carro.
3) Monty Hall sempre abre uma porta que tem uma cabra.
4) Se Monty Hall tem uma escolha, ele abre qualquer uma das duas portas com igual probabilidade.
Os pressupostos 1 e 2 estão explícitos no texto de Whitaker, e devem ser considerados, embora muitos leitores negligenciem o trecho que diz que o apresentador sabe em que porta está o carro.
O pressuposto 3 decorre do 2 e também está explícito no texto. Já vi, no entanto, ele ser omitido do enunciado em muitas ocasiões (devo dizer que já vi até mesmo o 2 ser omitido). Claro que poderíamos imaginar que o leitor já considere estas regras, já que, se Monty Hall não soubesse onde está o carro, ou pudesse, ainda que soubesse, abrir a porta que tem o carro, ele estragaria a brincadeira, terminando o jogo imediatamente. Porém, considero imprescindível que estas regras constem no enunciado – afinal, não se joga um jogo (ou se enuncia um problema) sem estabelecer as regras, não é mesmo? O pressuposto 4, finalmente, vem do fato de não temos nenhum elemento que leve a crer que os eventos não sejam equiprováveis (acho que não deveríamos supor que o apresentador seja um trapaceiro…).
Voltando à lógica de quem argumenta que não faz diferença trocar a porta, após elencar os pressupostos fica claro que esta idéia ignora todas as condições sob as quais o apresentador escolhe a porta que ele vai abrir. Ele não pode abrir a porta que você escolheu e, como vimos, não pode abrir a porta com o carro e deve escolher a porta que abrirá aleatoriamente quando tiver duas opções (ou seja, quando você escolher o carro logo de início). Suponha que Monty abra a porta 2. Se você considerar os pressupostos, entenderá que a informação que você acaba de receber foi de que o apresentador, que opera de acordo com certas regras, escolheu abrir a porta 2. A escolha de Monty foi feita por um dos dois motivos a seguir:
(a) O carro está atrás da porta 3, mas você escolheu a porta 1. Nesse caso, ele não podia ter aberto nem a porta 1 (que é a sua) e nem a porta 3 (que esconde o carro). Logo, foi forçado a abrir a porta 2. (b) O carro está atrás da porta 1, que foi a que você escolheu. Nesse caso, ele escolheu a porta 2 aleatoriamente entre a 2 e a 3. Se o apresentador escolhe a porta 2, é mais provável, então, que o carro esteja atrás da porta 3 do que da porta 1.
Acredito que isto ficará mais claro a seguir, quando eu apresentar a resolução em termos das probabilidades associadas. Por ora, o importante é entender que os pressupostos do problema, depreendidos de uma leitura minuciosa do enunciado, são cruciais para traçar uma estratégia. Quem primeiro vi destacar a importância de elencar os pressupostos do problema para o entendimento foi o professor Joe Blitzstein, da cadeira Stats 101, da Universidade de Harvard, cuja aula sobre Monty Hall está disponível em [6].
Uma resolução
Como mencionei no início do texto, existem inúmeras formas de resolução que levam à solução correta do problema. Pessoalmente, gosto de exibir os possíveis cenários usando uma árvore e calcular as probabilidades em seguida. Métodos gráficos, quando se estudam cenários, costumam ser úteis. Vamos começar a construir a árvore a partir das escolhas que podem ser feitas no início do jogo.
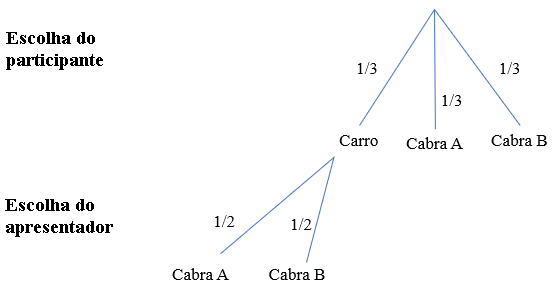
Primeiro, o participante tem uma entre três portas à sua escolha, uma com um carro e duas com cabras. Nesta primeira escolha, cada prêmio pode ser escolhido de maneira equiprovável, com probabilidade 1/3. A árvore começa então, assim:
Em seguida, o apresentador faz seu movimento. Vamos analisar o que acontece em cada um dos três casos: quando a porta que o participante escolheu tem um carro, a cabra A ou a cabra B. Quando a porta inicial do participante tem o carro, o apresentador pode abrir qualquer uma das duas outras portas e, como vimos, esta escolha é equiprovável. Portanto, cada uma das outras portas pode ser aberta com probabilidade 1/2. Acrescentamos este caminho à árvore:
Quando a porta inicial tem uma cabra, o apresentador é forçado a abrir a porta que tem a outra cabra. Como ele só tem uma escolha, e esta escolha deve obrigatoriamente ser feita, a probabilidade dela é 1. Acrescentando os caminhos para os casos em que a primeira porta tem a Cabra A ou a Cabra B, nossa árvore termina como a seguir:
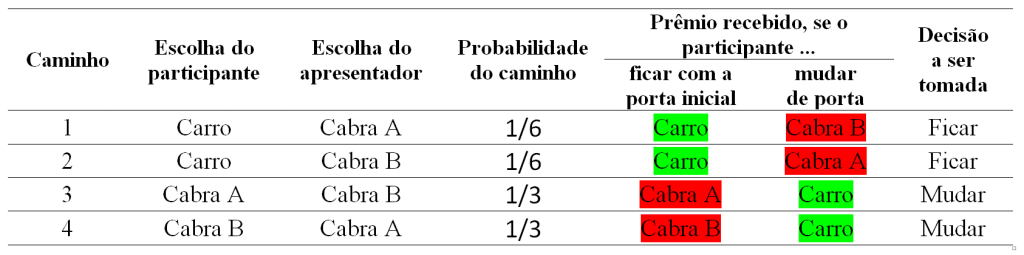
Vamos calcular as probabilidades de cada caminho (ou cada “cenário”, como queira). Como a escolha do participante e a escolha do apresentador são eventos independentes, a probabilidade do caminho será dada pelo produto das probabilidades dos ramos. As probabilidades de ocorrência dos caminhos da árvore, então, são as seguintes:
Agora vamos acrescentar mais duas informações à tabela: o que aconteceria a depender da estratégia (ficar com a porta escolhida inicialmente, ou mudar) e, com base nesta, a decisão final que o participante deveria tomar para maximizar sua possibilidade de ganhar o carro:
Da tabela, temos que:
i) A probabilidade ocorrer o caminho 1 ou o caminho 2 é de (1/6+1/6)=1/3.
Ou seja, a probabilidade de que o participante se veja em uma situação em que a melhor decisão seja ficar com a porta que escolheu inicialmente é de 1/3.
ii) A probabilidade ocorrer o caminho 3 ou o caminho 4 é de (1/3+1/3)=2/3.
Ou seja, a probabilidade de que o participante se veja em uma situação em que a melhor decisão seja mudar para a outra porta é de 2/3.
Como é mais provável que o participante se veja em uma situação em que mudar a porta é a melhor estratégia, concluímos que mudar a porta maximiza a probabilidade de se ganhar o carro. A estratégia recomendada, portanto, é sempre mudar de porta.
Palavras finais
O problema de Monty Hall é um exemplo clássico de como probabilidade é um assunto complexo. Um pequeno problema pode gerar controvérsias capazes de dar um nó nas mentes mais atentas, caso seus pressupostos não sejam claramente enunciados e observados. A quem se interessar pelo aprofundamento no tema, recomendo fortemente o livro de Rosenhouse [1], que não se atém ao problema original, mas também esmiúça algumas variantes muito curiosas.
*Guilherme Guilhermino Neto é professor no Instituto Federal do Espírito Santo (IFES).
Referências
[1] Rosenhause, Jason. 2009. The Monty Hall Problem: The Remarkable Story of Math’s Most Contentious Brain Teaser. Oxford University Press: Oxford.
[2] Selvin, Steve. 1957. “A Problem in Probability” (letter to the editor)”, American Statistician, Vol. 29, No. I, p. 67.
[4] Nalebuff, Barry. 1987. “Choose a Curtain, Duel-ity, Two Point Conversions and More”, Economic Perspectives, Puzzles Column, Vol. 1, No. 1, pp. 1 57-63.
Publish or Perish é uma expressão em inglês que descreve a situação de qualquer pesquisador hoje em dia: ou publica regularmente muitos artigos científicos, ou morre e é enterrado, em termos profissionais.
Isto acontece porque o número de publicações passou a ser usado como medida da produtividade; se um pesquisador não publica, corre o risco de perder o emprego. A situação não seria tão grave se atingisse apenas pesquisadores profissionais; contudo, atualmente os professores universitários e até os alunos de pós-graduação são também considerados “pesquisadores”, dentro do modelo de universidade proposto no século XIX por von Humboldt, e têm por isso que publicar muito.
Esta política de publicação forçada teve várias conseqüências negativas (e é discutível se teve alguma positiva). Uma delas foi o aumento explosivo do número de artigos que saem a cada ano. As estimativas variam, mas acredita-se que sejam publicados anualmente mais de dois milhões de artigos, e que existam pelo menos trinta mil revistas. A publicação científica se tornou um grande negócio. Para citar apenas um exemplo: a editora holandesa Elsevier controla 2.500 revistas, publicando em média meio milhão de artigos por ano, e tem um faturamento líquido nada desprezível de 600 milhões de dólares (dados da Wikipedia).
Outra conseqüência foi o aumento da pressão sobre os professores, que precisam arranjar algo para publicar todo ano – mesmo que não tenham nada particularmente importante a dizer. Com isto, sobra a eles menos tempo para se dedicarem ao ensino – o que aparentemente não é um problema, pois nas avaliações internacionais das universidades a quantidade de pesquisa é sempre um item de grande peso, enquanto a qualidade do ensino em geral não é nem mencionada.
Para aumentar os números, uma saída é diluir o conteúdo. No século XX, uma tese de doutorado concluída podia talvez dar um artigo internacional; hoje em dia, o mesma tese costuma ser repartida entre meia dúzia de artigos. Os leitores são forçados a ler todos eles, e têm que juntar as peças de um quebra-cabeças antes de entenderem os resultados.
Mesmo os pesquisadores sérios atualmente publicam demais. O artigo na Wikipedia sobre o astrônomo Carl Sagan, por exemplo, menciona orgulhosamente que ele teve mais de 600 “publicações científicas” (embora muitas sejam de divulgação, não de pesquisa). O mais prolífico parece ter sido o matemático húngaro Pál Erdős, que publicou em sua longa carreira 1.475 artigos, com 485 co-autores [1].
Se há hoje artigos demais, por outro lado há também autores demais – todos os que auxiliaram de alguma forma na pesquisa querem incluir seus nomes na lista de autores do artigo, para engordar os currículos. As revistas sérias tentam criar critérios para reduzir o número de “autores”, mas ainda é comum encontrarmos artigos com dezenas deles.
Uma coisa porém não mudou nas últimas décadas: se os manuais de redação do século XX diziam que as publicações científicas tendem a ser de leitura tediosa [2], porque os pesquisadores quase sempre escrevem mal [3], a situação não melhorou muito desde então. A maioria dos artigos continuam a ser enfadonhos, e seus autores não correm nenhum risco de ganhar o Prêmio Nobel de Literatura; correm, por outro lado, o risco de ganhar algo mais divertido, o prêmio IgNobel [4], uma paródia do Nobel, criada pelos alunos de Harvard. Se não ganham por causa da qualidade do texto, pelo menos podem ganhar por causa da situação ridícula que o artigo representa: por exemplo, autores demais para um mesmo artigo, ou artigos demais para um mesmo autor. Em 1993, o prêmio IgNobel de Literatura foi dado por um artigo publicado no The New England Journal of Medicine, uma das revistas médicas de maior prestígio internacional: o artigo de nove páginas tinha 976 autores. A editora da revista, que foi a Harvard receber o prêmio, estimou que havia em média um autor para cada duas palavras do artigo.
Em 1992, o prêmio foi dado ao russo Yuri Struchkov, por publicar nada menos que 948 artigos científicos. Alguém poderia argumentar que Pál Erdős publicou mais do que isto; mas é preciso considerar que Erdős passou uma longa vida publicando antes de alcançar o total (morreu aos 83 anos), e o último artigo foi publicado algumas semanas antes de sua morte. Struchkov, por outro lado, publicou os 948 artigos em apenas 10 anos (1981 – 1990), mantendo uma média de um artigo a cada 3,9 dias; e depois mais artigos com seu nome continuaram a aparecer, pelo menos até 1999 – embora ele tenha morrido em 1995. Erdős era realmente um autor prolífico, mas não conseguiu fazer a proeza de publicar quatro anos depois de morto…
Referências [1] Hoffman, P. The man who loved only numbers. London: Fourth State Ltd. 1998 [2] Calnan. J., Barabas, A. Writing medical papers – a practical guide. London: William Heinemann Medical Books Ltd. 1973. [3] Day, Robert A. How to write and publish a scientific paper. 5th ed. Cambridge University Press, 1998. [4] Abrahams, Marc. Ignobel prizes. London: Orion Books Ltd. 2003.
Quem já elaborou provas para alunos de graduação sabe como é difícil escrever enunciados que todos os alunos entendam. Por mais que a gente tente fazer um texto bem claro, sempre aparece alguém com interpretação diferente da que tínhamos em mente. Às vezes, esta interpretação não faz sentido e pode ser desconsiderada; às vezes, porém, mostra que o texto não estava claro, e a questão acaba tendo que ser anulada.
Do ponto de vista do aluno, parte de um problema é tentar entender o que o professor quis dizer. Suponhamos por exemplo este problema de Probabilidades:
Uma moeda é lançada duas vezes. Qual é a probabilidade de ela mostrar duas coroas?
Mesmo neste exemplo simples, o enunciado é vago, e os alunos têm que fazer várias pressuposições antes de começar a calcular. Primeiro, como não existem coroas nas faces das moedas brasileiras, têm que pressupor que coroa seja um termo genérico para indicar a face oposta à cara, independentemente do que esteja impresso na moeda. Segundo, têm que pressupor que “lançar” a moeda significa atirá-la para cima revolvendo em torno do diâmetro, de modo que as duas faces se alternem no lado superior; se lançarmos a moeda como um disco de frisbee (girando em torno de seu centro, com as faces paralelas ao solo), o problema não faz sentido. Terceiro, têm que pressupor que a moeda seja equilibrada, e P(cara) = P(coroa).
Como este é um problema padrão, e todos os alunos já viram algo parecido durante as aulas, estas pressuposições são feitas automaticamente, tanto pelos professores quanto pelos alunos. Se o problema tiver um enunciado um pouco diferente, porém, as coisas podem ser mais complicadas. Por exemplo, este problema:
Uma pessoa tem 10 pares de meias, que guarda misturadas numa gaveta. De manhã, ao acordar, pega aleatoriamente duas delas e as calça. Qual é a probabilidade de que estas duas meias formem um par?
A resposta que primeiro vem à mente da maioria dos alunos é P = 1/19. A primeira meia pode ser qualquer uma das 20 que estão na gaveta, por isso sua probabilidade é 20/20. A segunda deve ser a que forma um par com a primeira – só há uma destas entre as 19 meias que ficaram na gaveta, portanto sua probabilidade é 1/19. A resposta do problema é dada pelo produto das duas probabilidades: P = 20/20 x 1/19 = 19.
Está certo isto? Sim… ou não. Se você parte do pressuposto de que os 10 pares de meias são diferentes entre si, está correto. Mas o enunciado não exige isto – o que acontece se todos os pares forem iguais; por exemplo se todos forem pretos? Neste caso, a segunda meia pode ser qualquer uma, sua probabilidade é 19/19, e a resposta do problema passa a ser P = 20/20×19/19 = 1.
Está certo isto? Sim… ou não. Se você parte do pressuposto de que em cada par de meias o pé direito e o pé esquerdo são idênticos, está certo. Mas o que acontece se todos os pares forem iguais, mas em cada par o pé direito for diferente do esquerdo, como acontece em algumas meias esportivas?
Agora, se a primeira meia foi um pé direito, a segunda meia pode ser qualquer um dos 10 pés esquerdos que ficaram na gaveta, e sua probabilidade é 10/19; a resposta do problema é P = 20/20×10/19 = 10/19.
Há portanto três respostas diferentes, dependendo do que foi pressuposto (mas não explicitado) sobre as meias na gaveta. Usei este problema em várias provas para alunos de graduação, sem nunca ter notado que poderia haver dúvidas na interpretação, e os alunos sempre responderam da primeira forma (P=1/19). Todos partiram do pressuposto de que os pares são sempre diferentes entre si.
A única dificuldade com o enunciado foi a de um aluno que me chamou de lado durante uma prova e me disse baixinho “Professor, não estou entendendo isto… Sei fazer o problema das meias, mas não entendi esta parte das ‘calça’ – o que tem ‘as calça’ a ver com ‘as meia’?”
No primeiro problema mostrado em seu Essai Philosophique sur les Probabilités, Laplace lança uma moeda duas vezes e calcula a probabilidade de aparecer pelo menos uma cara. Desde então, praticamente todos os livros seguem o exemplo de Laplace, e começam a ensinar probabilidades com problemas de cara ou coroa – este jogo se tornou uma ferramenta básica no ensino porque é simples, fácil de reproduzir na sala de aula e, principalmente, porque é razoável pressupormos, como fizeram Pascal, Fermat e Laplace, que a probabilidade da cara é igual à da coroa, e podemos começar a fazer as contas a partir daí.
A maioria dos estudantes já ouviram a expressão “cara ou coroa”, mas em geral não sabem como surgiu, porque nunca viram uma coroa numa moeda. Coroas, é claro, aparecem nas moedas de países com regime monárquico, como eram no passado quase todos os países europeus. A foto mostra um dobrão espanhol de 1798, que tem de um lado a cara do rei Dom Carlos IV, aparentemente muito satisfeito, e do outro o brasão e a coroa reais.
Algumas moedas de países cristãos tinham cruzes, no lugar das caras, como o dobrão português emitido por D. João V, em 1725 (bem conhecida pelos colecionadores, pois é a moeda de maior valor intrínseco já cunhada). Em seus livros, Laplace chama os dois lados da moeda de croix e pile (croix: cruz, pile: lado da moeda onde estão as armas do rei, ou o valor da moeda).
As últimas moedas brasileiras que tinham caras e coroas foram emitidas nos fins do Império, como esta de 2000 réis de 1886; de um lado, está a cara de Dom Pedro II, do outro o brasão e a coroa imperial. (Foto: en.numista.com)
Atualmente, o Reino Unido é um dos poucos países de destaque na economia mundial que ainda usam moedas assim; a foto ao lado mostra a moeda de uma libra, que tem de uma lado a cara da rainha Elizabeth II, do outro a coroa real. Note que nesta moeda não há lugar para o número; o valor está escrito por extenso abaixo da coroa (one pound).
É um fato curioso que cada uma das línguas mais faladas do mundo dê um nome diferente para o jogo, e no entanto nenhum deles seja tradução literal de cara ou coroa. Na França, o jogo é chamado atualmente de pileou face. Na Espanha, de cara o cruz (mas os países da América Latina usam várias outras expressões diferentes veja a lista na Wikipedia); na Itália, de testa o croce (testa: cabeça; croce: cruz); na Hungria, de fej vagy írás (cabeça ou escrito). No Reino Unido, um dos poucos países cuja moeda realmente tem cara e coroa, usa-se uma expressão totalmente diferente, heads or tails (head: cabeça; tail: rabo ou cauda) – que parece um tanto desrespeitosa quando aplicada à Rainha…
O nome cara ou coroa ficou, mas as moedas brasileiras atuais já não têm coroas; às vezes, não têm nem mesmo caras, como algumas das moedas de cruzeiro que circularam nos anos 1980s. O mesmo acontece no resto do mundo; os nomes ficam, mas as moedas mudam – em quase todas as línguas o que pode ser visto na moeda já não corresponde ao nome do jogo. A foto abaixo mostra algumas das moedas que circulam na Comunidade Européia. O lado que tem o valor (2 euros) é igual em toda a Comunidade (A); o que está do outro lado, porém, pode variar, dependendo do país onde a moeda foi cunhada.
A da Alemanha (B) mostra uma águia, símbolo do país. A da França (C) não tem nem cruz nem face, mas uma árvore estilizada e o lema da revolução francesa, Liberté, Égalité, Fraternité. A da Espanha (D) é curiosa: como o país é uma monarquia, a moeda mostra a cara do rei Dom Carlos e, ao seu lado, uma letra M, sobre a qual está colocada uma minúscula coroa. Esta moeda, portanto, tem cara e coroa do mesmo lado.
A expressão cara ou coroa é uma daquelas que permanecem na língua, mesmo quando já perderam seu sentido literal. Em toda língua sobrevivem estas expressões antiquadas; ainda falamos do nascer do sol, ou pôr do sol, mesmo sabendo que não é o Sol que sobe ou desce, mas sim a Terra que se move; ou falamos do fim do mundo, mesmo sabendo que na superfície de uma esfera não existe um fim. Estas expressões existem há séculos, e fazem parte do patrimônio da língua. As expressões que apareceram recentemente e se referem a tecnologias, no entanto, envelhecem muito rápido, perdem o sentido literal de uma geração para a outra e provavelmente acabam desaparecendo. A maioria dos alunos ainda entende o que significa queimar o filme, virar o disco, cair a ficha ou dar tilt na máquina; quantos deles porém seriam capazes de dizer o que significam literalmente estas expressões?
Ler dicionários pode não ser um passatempo muito popular, mas certamente nos faz aprender algumas coisas interessantes. Por exemplo, dicionários nos mostram como o resto do mundo define a nossa profissão ou área de estudo. Todos sabem, mais ou menos, o que é Medicina, Matemática ou Direito. Mas quantos saberiam dizer o que é Mecatrônica? Ou Sistemas de Informação? Ou Estatística?
Além disso, dicionários de diferentes épocas nos mostram como a profissão ou área mudou ao longo do tempo. Todos os dicionários incluem a Matemática, que é mais antiga do que qualquer dicionário, e as definições não variam muito; poucos incluem a Mecatrônica. Todos incluem a Estatística, mas as definições foram sendo modificadas com o passar do tempo, acompanhando a evolução ocorrida no último século.
O primeiro dicionário da língua portuguesa foi o de Moraes Silva; a primeira edição é de 1789 (disponível online), mas não tem a palavra ‘estatística’. A edição que tenho é a 9ª.; não está datada, mas parece ser de c. 1890.
Estatística: 1. Ciência que ensina a conhecer um estado com relação à sua extensão, povoação, agricultura, administração, instrução, marinha, indústria, comércio, etc. (…) 4. Estatística médica: relação, enumeração das mortes, nascimentos, doenças individuais, endêmicas ou epidêmicas num dado período. num dado país, cidade, etc.; demografia. [1]
Outro dicionário antigo importante é o de Caldas Aulete. Na edição de 1881, a Estatística é definida como:
Estatística. A sciencia dos factos sociaes expressos em termos numericos, a qual ensina a conhecer uma nação debaixo do ponto de vista da sua extensão, população, industria, agricultura, administracção, instrucção, força militar, marinha, commercio, etc., em um momento dado. [2]
Nestas duas definições, o que é chamado de “Estatística” é aquilo que hoje chamamos de Estatística Descritiva: um conjunto de técnicas para organizar e resumir grandes quantidades de dados; geralmente, para descrever um “estado” (um país, região, cidade, etc.). Se a Estatística se limitasse a isto, seria certamente útil para a geógrafos, demógrafos, administradores, médicos que trabalham em saúde pública, e pesquisadores em áreas voltadas para populações; mas provavelmente não iria interessar muito a biólogos, físicos, engenheiros, tecnólogos, etc.
No início do século XX, as coisas começaram a mudar. Galton, Pearson e Fisher lançaram nesta época as bases da Inferência, que um dicionário especializado define como “O processo de tirar conclusões sobre uma população com base em medidas ou observações feitas numa amostra de unidades desta população” [3]. Contudo, nem o Larousse (c. 1910), nem o dicionário da Academia espanhola (1939) ainda não iam além da Estatística Descritiva, e não usavam as palavras inferência, probabilidade ou amostras em suas definições:
Estatística: ciência que tem por objeto o agrupamento metódico dos fatos sociais que se prestam à avaliação numérica (impostos, recrutamento, condenações, produções industriais e agrícolas, população, religião, etc. [4]
Estatística: 1. Censo ou recontagem da população, recursos naturais e industriais, trânsito ou qualquer outra manifestação de estado, província, município, classe, etc. 2. Estudo dos fatos morais ou físicos do mundo que se prestam à numeração ou contagem e à comparação dos números que lhes dizem respeito. [5]
No final do século, as definições dadas pela Enciclopédia Britânica e dois dicionários americanos (anos 1970-1980s), tomadas em conjunto, definem bem o escopo da Inferência; contudo, as que usam a palavra inferência não usam probabilidade, e vice-versa, e só uma delas menciona amostras:
Estatística: na matemática, diz respeito a qualquer tipo de coleta de dados numéricos, e aos processos de analisar e fazer inferências a partir dos dados. [6]
Estatística: a ciência que lida com a coleta, classificação, análise e interpretação de fatos e dados numéricos, e que, usando a teoria das probabilidades, impõe ordem e regularidade a agregados de elementos mais ou menos disparatados. [7]
Estatística. A matemática da coleção, organização e interpretação de dados numéricos, especialmente a análise das características de populações por inferência a partir de amostragem. [8]
No Brasil, os dois dicionários mais importantes são provavelmente o Aurélio e o Houaiss. O verbete do Aurélio é longo, incluindo cinco itens. O primeiro é:
Estatística: 1. Parte da Matemática em que se investigam os processos de obtenção, organização e análise de dados sobre uma população ou sobre uma coleção de seres quaisquer, e os métodos de tirar conclusões e fazer ilações ou predições com base nesses dados. [9]
A definição é abrangente, porque sugere que a Estatística também inclui disciplinas para “obtenção … de dados” (como a Amostragem e o Planejamento de experimentos), além das técnicas para “organização e análise dos dados” (Estatística descritiva), e para “fazer ilações” (Inferência) com base nos dados; não menciona porém que os dados se originam de amostras, ou que estas ilações são baseadas em probabilidades. A definição do Houaiss é menos interessante:
Estatística. 1. Ramo da matemática que trata da coleta, da análise, da interpretação e da apresentação de massas de dados numéricos. 2. qualquer coleta de dados quantitativos. [10]
Se os dicionários convencionais não parecem acertar com uma definição adequada de Estatística, o que dizem os dicionários especializados, escritos por estatísticos? Este é o problema: geralmente não dizem nada. Dois dos dicionários técnicos mais conhecidos atualmente, o de Porkess [11] e o da Universidade de Cambridge [3], não têm um verbete “Estatística” (embora tenham o termo técnico “estatística”: uma função definida sobre os dados de uma amostra).
Que conclusão podemos tirar disto tudo – o que os leigos pensam que é a Estatística? Os verbetes citados acima sugerem que o conceito de Estatística descritiva é bem compreendido pelos leigos (que escrevem os dicionários), mas o conceito de Inferência não está claro para eles. Estes verbetes não enfatizam o que me parece o mais importante: o fato de que todas as conclusões estatísticas são baseadas na teoria de Probabilidades, e portanto são sempre incertas e sujeitas a erros.
O público em geral quer que haja certeza nos resultados obtidos por estatísticos e cientistas; no entanto, como Richard Feynman sempre enfatizou ao longo de sua carreira divulgando a Física (um capítulo de seus livros tem justamente o título de The Uncertainty of Science [12]), toda conclusão científica é incerta e provisória. Mostrar que a incerteza é inerente a todo o conhecimento humano, e que a Inferência é a ferramenta de que dispomos para lidar com ela, pode ser por isso a melhor maneira de despertar o interesse do público pela Estatística.
Textos originais [todas as traduções são minhas]:
Inference. The process of drawing conclusions about a population on the basis of measurements or observations made on a sample of units from the population. [3]
Statistique: science qui a pour objet le groupement méthodique des faits sociaux qui se prêtent à une évaluation numérique (impôts, recrutement, condamnations, productions industrielles et agricoles, population, religion, etc. [4]
Estadística. Censo o recuento de la población, de los recursos naturales e industriales, del tráfico o de cualquier otra manifestación de un estado, provincia, pueblo, clase, etc. | 2. Estudio de los hechos morales o físicos del mundo que se prestan a numeración o recuento y a comparación de las cifras a ellos referentes. [5]
Statistics. in mathematics, concern any kind of numerical data gathering and the processes of analyzing and of making inferences from the data. [6]
Statistics: the science that deals with the collection, classification, analysis and interpretation of numerical facts or data, and that, by use of mathematical theory of probability, imposes order and regularity on aggregates of more or less disparate elements. [7]
Statistics. The mathematics of the collection, organization, and interpretation of numerical data, esp. the analysis of population characteristics by inference from sampling. [8]
 Em 1992, ocorreu um incidente curioso no mercado americano de brinquedos. A Mattel, fábrica da Barbie, lançou o modelo Teen Talk Barbie, que tinha dentro um gravador: quando a criança apertava um botão, a boneca dizia algumas frases pré-gravadas. A idéia era uma novidade na época, e a boneca começou a vender muito bem (mais de 300 mil unidades em um ano). A maior parte das frases eram as tolices que se esperaria que saíssem de uma Barbie (“Ok, me encontre no shopping”, “Será que um dia nós teremos roupas que chegam?”, “Quer sair pra fazer compras?”, etc.).
Em 1992, ocorreu um incidente curioso no mercado americano de brinquedos. A Mattel, fábrica da Barbie, lançou o modelo Teen Talk Barbie, que tinha dentro um gravador: quando a criança apertava um botão, a boneca dizia algumas frases pré-gravadas. A idéia era uma novidade na época, e a boneca começou a vender muito bem (mais de 300 mil unidades em um ano). A maior parte das frases eram as tolices que se esperaria que saíssem de uma Barbie (“Ok, me encontre no shopping”, “Será que um dia nós teremos roupas que chegam?”, “Quer sair pra fazer compras?”, etc.). O exemplo mais bem conhecido é o de d’Alembert (1717- 1783), matemático, físico e filósofo francês (retratado ao lado por Quentin de La Tour, 1753). D’Alembert foi um dos editores da Encyclopédie – a enciclopédia francesa que, junto com a inglesa Encyclopaedia Britannica e a alemã Brockhaus Enzyklopädie, foram no século XVIII as precursoras das enciclopédias modernas. Entre os cerca de 1700 textos que escreveu para a obra estava o artigo “Croix ou Pile” (cara-ou-coroa), no qual d’Alembert afirmava que a probabilidade de se obter pelo menos uma cara no lançamentos de duas moedas não é ¾ (como afirmavam Pascal e Fermat), mas sim 2/3. Uma vez que o jogo pára se houver cara na primeira moeda (não é preciso jogar de novo a moeda, se já saiu uma cara), há apenas três resultados possíveis: cara na primeira moeda; cara na segunda moeda; coroa nas duas moedas. Laplace fez referência a este erro no seus livro clássico [1], publicado muito depois, o que tornou d’Alembert célebre não apenas por seus muitos acertos, mas também por este único erro. O historiador Charles Boyer chegou a afirmar que “D´Alembert, diferentemente de Euler, é notado na história das Probabilidades principalmente por ter se oposto às opiniões geralmente aceitas” [2], o que é um exagero (a Wikipedia traz uma longa lista das contribuições de d’Alembert à Matemática).
O exemplo mais bem conhecido é o de d’Alembert (1717- 1783), matemático, físico e filósofo francês (retratado ao lado por Quentin de La Tour, 1753). D’Alembert foi um dos editores da Encyclopédie – a enciclopédia francesa que, junto com a inglesa Encyclopaedia Britannica e a alemã Brockhaus Enzyklopädie, foram no século XVIII as precursoras das enciclopédias modernas. Entre os cerca de 1700 textos que escreveu para a obra estava o artigo “Croix ou Pile” (cara-ou-coroa), no qual d’Alembert afirmava que a probabilidade de se obter pelo menos uma cara no lançamentos de duas moedas não é ¾ (como afirmavam Pascal e Fermat), mas sim 2/3. Uma vez que o jogo pára se houver cara na primeira moeda (não é preciso jogar de novo a moeda, se já saiu uma cara), há apenas três resultados possíveis: cara na primeira moeda; cara na segunda moeda; coroa nas duas moedas. Laplace fez referência a este erro no seus livro clássico [1], publicado muito depois, o que tornou d’Alembert célebre não apenas por seus muitos acertos, mas também por este único erro. O historiador Charles Boyer chegou a afirmar que “D´Alembert, diferentemente de Euler, é notado na história das Probabilidades principalmente por ter se oposto às opiniões geralmente aceitas” [2], o que é um exagero (a Wikipedia traz uma longa lista das contribuições de d’Alembert à Matemática). Saber que existia um livro de 194 páginas inteiramente dedicado ao problema já me trouxe algum conforto: se tanto havia para falar sobre um único problema, talvez não houvesse tanto motivo para eu me culpar por não me satisfazer com as respostas, porque o negócio seria realmente complexo. Ao longo de um divertido primeiro capítulo, Rosenhouse deixa claro que eu não estava mesmo sozinho (inclusive estava muito bem acompanhado): por anos, o problema foi motivo de controvérsia e muita discussão, até mesmo entre matemáticos de primeira linha!
Saber que existia um livro de 194 páginas inteiramente dedicado ao problema já me trouxe algum conforto: se tanto havia para falar sobre um único problema, talvez não houvesse tanto motivo para eu me culpar por não me satisfazer com as respostas, porque o negócio seria realmente complexo. Ao longo de um divertido primeiro capítulo, Rosenhouse deixa claro que eu não estava mesmo sozinho (inclusive estava muito bem acompanhado): por anos, o problema foi motivo de controvérsia e muita discussão, até mesmo entre matemáticos de primeira linha!







 Atualmente, o Reino Unido é um dos poucos países de destaque na economia mundial que ainda usam moedas assim; a foto ao lado mostra a moeda de uma libra, que tem de uma lado a cara da rainha Elizabeth II, do outro a coroa real. Note que nesta moeda não há lugar para o número; o valor está escrito por extenso abaixo da coroa (one pound).
Atualmente, o Reino Unido é um dos poucos países de destaque na economia mundial que ainda usam moedas assim; a foto ao lado mostra a moeda de uma libra, que tem de uma lado a cara da rainha Elizabeth II, do outro a coroa real. Note que nesta moeda não há lugar para o número; o valor está escrito por extenso abaixo da coroa (one pound).
